 Posted by S.SURYA NARAYAN on March 16, 2014, 8:52 p.m.
Posted by S.SURYA NARAYAN on March 16, 2014, 8:52 p.m.
Online machine learning is a model of induction that learns one instance at a time. The goal in on-line learning is to predict labels for instances. For example, the instances could describe the current conditions of the stock market, and an online algorithm predicts tomorrow's value of a particular stock. The key defining characteristic of on-line learning is that soon after the prediction is made, the true label of the instance is discovered. This information can then be used to refine the prediction hypothesis used by the algorithm. The goal of the algorithm is to make predictions that are close to the true labels.
More formally, an online algorithm proceeds in a sequence of trials. Each trial can be decomposed into three steps. First the algorithm receives an instance. Second the algorithm predicts the label of the instance. Third the algorithm receives the true label of the instance.[1] The third stage is the most crucial as the algorithm can use this label feedback to update its hypothesis for future trials. The goal of the algorithm is to minimize some performance criteria. For example, with stock market prediction the algorithm may attempt to minimize sum of the square distances between the predicted and true value of a stock. Another popular performance criterion is to minimize the number of mistakes when dealing with classification problems. In addition to applications of a sequential nature, online learning algorithms are also relevant in applications with huge amounts of data such that traditional learning approaches that use the entire data set in aggregate are computationally infeasible.
Because on-line learning algorithms continually receive label feedback, the algorithms are able to adapt and learn in difficult situations. Many online algorithms can give strong guarantees on performance even when the instances are not generated by a distribution. As long as a reasonably good classifier exists, the online algorithm will learn to predict correct labels. This good classifier must come from a previously determined set that depends on the algorithm. For example, two popular on-line algorithms perceptron and winnow can perform well when a hyperplane exists that splits the data into two categories. These algorithms can even be modified to do provably well even if the hyperplane is allowed to infrequently change during the on-line learning trials.
Unfortunately, the main difficulty of on-line learning is also a result of the requirement for continual label feedback. For many problems it is not possible to guarantee that accurate label feedback will be available in the near future. For example, when designing a system that learns how to do optical character recognition, typically some expert must label previous instances to help train the algorithm. In actual use of the OCR application, the expert is no longer available and no inexpensive outside source of accurate labels is available. Fortunately, there is a large class of problems where label feedback is always available. For any problem that consists of predicting the future, an on-line learning algorithm just needs to wait for the label to become available. This is true in our previous example of stock market prediction and many other problems.
A prototypical online supervised learning algorithm
In the setting of supervised learning, or learning from examples, we are interested in learning a function  , where
, where  is thought of as a space of inputs and
is thought of as a space of inputs and  as a space of outputs, that predicts well on instances that are drawn from a joint probability distribution
as a space of outputs, that predicts well on instances that are drawn from a joint probability distribution  on
on  . In this setting, we are given a loss function
. In this setting, we are given a loss function  , such that
, such that  measures the difference between the predicted value
measures the difference between the predicted value  and the true value
and the true value  . The ideal goal is to select a function
. The ideal goal is to select a function  , where
, where 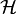 is a space of functions called a hypothesis space, so as to minimize the expected risk:
is a space of functions called a hypothesis space, so as to minimize the expected risk:
![I[f] = \mathbb{E}[V(f(x), y)] = \int V(f(x), y)\,dp(x, y) \ .](http://upload.wikimedia.org/math/c/2/8/c28b0cf5e1e883b885ff52468adbb967.png)
In reality, the learner never knows the true distribution over instances. Instead, the learner usually has access to a training set of examples  that are assumed to have been drawn i.i.d. from the true distribution . A common paradigm in this situation is to estimate a function
that are assumed to have been drawn i.i.d. from the true distribution . A common paradigm in this situation is to estimate a function 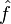 through empirical risk minimization or regularized empirical risk minimization (usually Tikhonov regularization). The choice of loss function here gives rise to several well-known learning algorithms such as regularized least squares and support vector machines.
through empirical risk minimization or regularized empirical risk minimization (usually Tikhonov regularization). The choice of loss function here gives rise to several well-known learning algorithms such as regularized least squares and support vector machines.
The above paradigm is not well-suited to the online learning setting though, as it requires complete a priori knowledge of the entire training set. In the pure online learning approach, the learning algorithm should update a sequence of functions  in a way such that the function
in a way such that the function  depends only on the previous function
depends only on the previous function 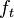 and the next data point
and the next data point 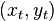 . This approach has low memory requirements in the sense that it only requires storage of a representation of the current function and the next data point . A related approach that has larger memory requirements allows to depend on and all previous data points
. This approach has low memory requirements in the sense that it only requires storage of a representation of the current function and the next data point . A related approach that has larger memory requirements allows to depend on and all previous data points  . We focus solely on the former approach here, and we consider both the case where the data is coming from an infinite stream
. We focus solely on the former approach here, and we consider both the case where the data is coming from an infinite stream  and the case where the data is coming from a finite training set , in which case the online learning algorithm may make multiple passes through the data.
and the case where the data is coming from a finite training set , in which case the online learning algorithm may make multiple passes through the data.
The algorithm and its interpretations[edit]
Here we outline a prototypical online learning algorithm in the supervised learning setting and we discuss several interpretations of this algorithm. For simplicity, consider the case where  ,
,  , and
, and  is the set of all linear functionals from into
is the set of all linear functionals from into 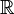 , i.e. we are working with a linear kernel and functions can be identified with vectors
, i.e. we are working with a linear kernel and functions can be identified with vectors  . Furthermore, assume that
. Furthermore, assume that  is a convex, differentiable loss function. An online learning algorithm satisfying the low memory property discussed above consists of the following iteration:
is a convex, differentiable loss function. An online learning algorithm satisfying the low memory property discussed above consists of the following iteration:

where  ,
,  is the gradient of the loss for the next data point evaluated at the current linear functional
is the gradient of the loss for the next data point evaluated at the current linear functional  , and
, and  is a step-size parameter. In the case of an infinite stream of data, one can run this iteration, in principle, forever, and in the case of a finite but large set of data, one can consider a single pass or multiple passes (epochs) through the data.
is a step-size parameter. In the case of an infinite stream of data, one can run this iteration, in principle, forever, and in the case of a finite but large set of data, one can consider a single pass or multiple passes (epochs) through the data.
Interestingly enough, the above simple iterative online learning algorithm has three distinct interpretations, each of which has distinct implications about the predictive quality of the sequence of functions  . The first interpretation considers the above iteration as an instance of the stochastic gradient descent method applied to the problem of minimizing the expected risk
. The first interpretation considers the above iteration as an instance of the stochastic gradient descent method applied to the problem of minimizing the expected risk ![I[w]](http://upload.wikimedia.org/math/9/4/0/9408c23ce3d3e3da2c12ff0f451453c7.png) defined above. [2] Indeed, in the case of an infinite stream of data, since the examples are assumed to be drawn i.i.d. from the distribution , the sequence of gradients of in the above iteration are an i.i.d. sample of stochastic estimates of the gradient of the expected risk and therefore one can apply complexity results for the stochastic gradient descent method to bound the deviation
defined above. [2] Indeed, in the case of an infinite stream of data, since the examples are assumed to be drawn i.i.d. from the distribution , the sequence of gradients of in the above iteration are an i.i.d. sample of stochastic estimates of the gradient of the expected risk and therefore one can apply complexity results for the stochastic gradient descent method to bound the deviation ![I[w_t] - I[w^\ast]](http://upload.wikimedia.org/math/2/2/6/22603906cb4a251e1d54814641d1541b.png) , where
, where  is the minimizer of . [3] This interpretation is also valid in the case of a finite training set; although with multiple passes through the data the gradients are no longer independent, still complexity results can be obtained in special cases.
is the minimizer of . [3] This interpretation is also valid in the case of a finite training set; although with multiple passes through the data the gradients are no longer independent, still complexity results can be obtained in special cases.
The second interpretation applies to the case of a finite training set and considers the above recursion as an instance of the incremental gradient descent method[4] to minimize the empirical risk:
![I_n[w] = \frac{1}{n}\sum_{i = 1}^nV(\langle w,x_i \rangle, y_i) \ .](http://upload.wikimedia.org/math/2/a/4/2a4929b0e538c9db0a64086fa22c77bb.png)
Since the gradients of in the above iteration are also stochastic estimates of the gradient of ![I_n[w]](http://upload.wikimedia.org/math/5/4/d/54d900f70f330b955bd353b5655bd790.png) , this interpretation is also related to the stochastic gradient descent method, but applied to minimize the empirical risk as opposed to the expected risk. Since this interpretation concerns the empirical risk and not the expected risk, multiple passes through the data are readily allowed and actually lead to tighter bounds on the deviations
, this interpretation is also related to the stochastic gradient descent method, but applied to minimize the empirical risk as opposed to the expected risk. Since this interpretation concerns the empirical risk and not the expected risk, multiple passes through the data are readily allowed and actually lead to tighter bounds on the deviations ![I_n[w_t] - I_n[w^\ast_n]](http://upload.wikimedia.org/math/6/f/5/6f52c1a158399bcfc9c9b42e3cb3be63.png) , where
, where  is the minimizer of .
is the minimizer of .
The third interpretation of the above recursion is distinctly different from the first two and concerns the case of sequential trials discussed above, where the data are potentially not i.i.d. and can perhaps be selected in an adversarial manner. At each step of this process, the learner is given an input 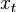 and makes a prediction based on the current linear function . Only after making this prediction does the learner see the true label
and makes a prediction based on the current linear function . Only after making this prediction does the learner see the true label 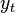 , at which point the learner is allowed to update to
, at which point the learner is allowed to update to  . Since we are not making any distributional assumptions about the data, the goal here is to perform as well as if we could view the entire sequence of examples ahead of time; that is, we would like the sequence of functions to have low regret relative to any vector:
. Since we are not making any distributional assumptions about the data, the goal here is to perform as well as if we could view the entire sequence of examples ahead of time; that is, we would like the sequence of functions to have low regret relative to any vector:

In this setting, the above recursion can be considered as an instance of the online gradient descent method for which there are complexity bounds that guarantee  regret.
regret.
It should be noted that although the three interpretations of this algorithm yield complexity bounds in three distinct settings, each bound depends on the choice of step-size sequence  in a different way, and thus we cannot simultaneously apply the consequences of all three interpretations; we must instead select the step-size sequence in a way that is tailored for the interpretation that is most relevant. Furthermore, the above algorithm and these interpretations can be extended to the case of a nonlinear kernel by simply considering to be the feature space associated with the kernel. Although in this case the memory requirements at each iteration are no longer
in a different way, and thus we cannot simultaneously apply the consequences of all three interpretations; we must instead select the step-size sequence in a way that is tailored for the interpretation that is most relevant. Furthermore, the above algorithm and these interpretations can be extended to the case of a nonlinear kernel by simply considering to be the feature space associated with the kernel. Although in this case the memory requirements at each iteration are no longer  , but are rather on the order of the number of data points considered so far.
, but are rather on the order of the number of data points considered so far.